一、AI大模型简介
AI模型最初是针对特定应用场景需求进行训练(即小模型)。小模型的通用性差,换到另一个应用场景中可能并不适用,需要重新训练,这牵涉到很多调参、调优的工作及成本。同时,由于模型训练需要大规模的标注数据,在某些应用场景的数据量少,训练出来的模型精度不理想的情况,这使得AI研发成本高,效率低的情况。随着数据,算力及算法的提升,AI技术也有了变化,从过去的小模型到大模型的兴起。大模型就是Foundation Model(基础模型),指通过在大规模宽泛的数据上进行训练后能适应一系列下游任务的模型。大模型兼具“大规模”和“预训练”两种属性,面向实际任务建模前需在海量通用数据上进行预先训练,能大幅提升人工智能的泛化性、通用性、实用性,是人工智能迈向通用智能的里程碑技术。
二、AI大模型总数
相比传统AI模型,AI大模型可解决AI过于碎片化和多样化的问题,极大提高模型的泛用性;具备自监督学习功能,降低训练研发成本;摆脱结构变革桎梏,打开模型精度上限。AI大模型优势突出,成为全球发展浪潮。截至2023年5月,美国已发布100个参数规模10亿以上的大模型。中国亦积极跟进,自2021年以来加速产出,截至2023年10月,我国AI大模型总数已达238个,在全球范围占据先发优势。
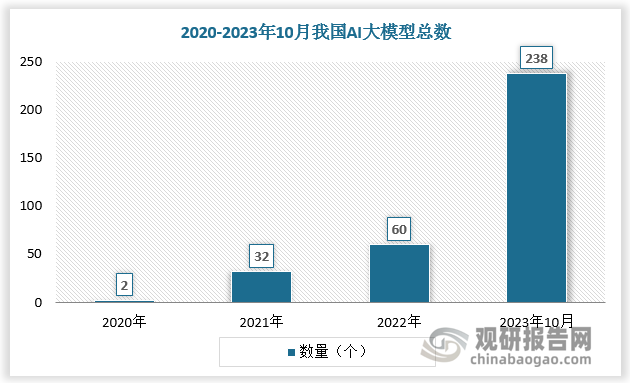
数据来源:观研天下数据中心整理
三、AI大模型地区发展情况
根据观研报告网发布的《中国AI大模型行业发展现状分析与投资前景研究报告(2024-2031年)》显示,从地区发展情况看,北京市连续出台了《加快建设具有全球影响力的人工智能创新策源地实施方案》《北京市促进通用人工智能创新发展的若干措施》《北京市通用人工智能产业创新伙伴计划》等多项支持政策,释放明确信号、搭建伙伴平台、聚拢行业资源,助力AI大模型发展。在良好环境下北京已成为当前国内大模型数量最多,质量最高的地区。
北京市大模型相关政策
| 政策 | 主要内容 |
| 《北京市促进通用人工智能创新发展的若干措施》 | 系统构建大模型等通用人工智能技术体系 |
| 《北京市通用人工智能产业创新伙伴计划》 | 上下游产业链布局持续优化优质算力、高质量数据供给支撑能力大幅提升,大模型创新应用引领全国,每年落地10个以上重点场景商业化标杆应用并形成10个以上行业标杆解决方案,培育一批应用大模型技术实现突破性成长的标杆企业,建成具有国际影响力的通用人工智能产业发展高地 |
| 《北京市加快建设具有全球影响力的人工智能创新策源地实施方案(2023-2025年)》 | 引领人工智能关键核心技术创新,支持创新主体重点突破分布式高效深度学习框架、大模型新型基础架构、深度超大规模图计算、超大规模模拟计算等基础平台技术 |
| 《北京市促进未来产业创新发展实施方案》 | 重点支持机器人技术与多模态大模型融合发展 |
资料来源:观研天下整理
根据数据,截至2023年10月,北京市AI大模型数量达115个,占全国AI大模型总数量的比重接近50%。截至2023年7月,中文综合能力排名前15名的大模型参数规模基本在百亿以上,其中过半大模型企业在北京。
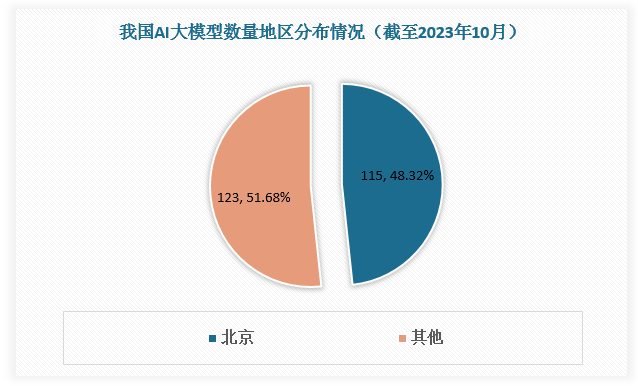
数据来源:观研天下数据中心整理
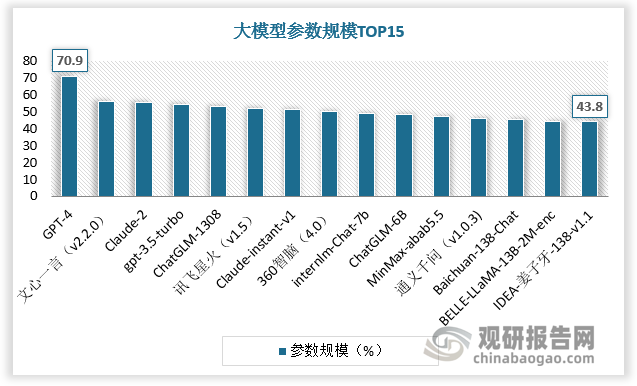
数据来源:观研天下数据中心整理
四、AI大模型市场竞争
技术投入、核心人才和应用场景构成AI大模型核心壁垒,当前国内仍处研发和迭代的早期阶段,各个大模型的性能差异及易用性仍在市场检验的过程当中,竞争格局的明晰仍需一定时间。目前百度、阿里、腾讯、字节跳动等互联网巨头在研发、模型、数据、应用等方面具备优势,布局完备,竞争力相对较强。
互联网巨头优势
| 优势 | 简介 |
| 算法模型 | 追随海外技术进展,研发突破是竞争关键。从技术路线来看,国内大模型主要追随海外进展。基于谷歌在人工智能领域更高的影响力以及BERT开源代码,前期我国企业在大模型领域的探索更多参考BERT路线。随着ChatGPT在人机对话领域的超预期表现验证了高质量数据+反馈激励(大模型预训练+小数据微调)的有效性,国内大模型技术路线也逐渐向GPT方向收敛。尽管模型架构设计的不同对特定任务上的表现有一定影响,但国内大模型厂商在技术上基本同源,从而导致了现阶段较为相似的模型能力,而下一阶段对于GPT方向的研发突破将是竞争关键。 |
| 算力 | 1)互联网企业业务布局多元,用户基数庞大,海量数据高频更新,使得互联网企业自身对算力有大量需求,阿里、字节、百度、腾讯等头部互联网企业是全球芯片及服务器领域的重要客户。2)阿里云、百度云、腾讯云等为国内头部云厂商,在云计算中心、AI算力平台、超算中心等新型高性能计算基础设施上布局领先,如阿里云推出PAI灵骏智算服务,提供覆盖AI开发全流程的平台和分布式异构计算优化能力;腾讯云发布新一代HCC(High-PerformanceComputingCluster)高性能计算集群,算力性能较前代提升高达3倍。 |
| 数据 | 优质开源中文数据集稀缺,自有数据及处理能力构成模型训练壁垒。得益于开源共创的互联网生态,海外已有大量优质、结构化的开源数据库,文本来源既包含严谨的学术写作、百科知识,也包含文学作品、新闻媒体、社交网站、流行内容等,更加丰富的语料数据能够提高模型在不同情景下的对话能力。而受制于搭建数据集较高的成本以及尚未成熟的开源生态,国内开源数据集在数据规模和语料质量上相比海外仍有较大差距,数据来源较为单一,且更新频率较低,从而导致模型的训练效果受限。因此,大模型厂商的自有数据和处理能力构成模型训练效果差异化的核心。受益于移动互联网时代积累的海量用户、应用和数据,互联网企业在自有数据上更具特色化和独占性,叠加更强大的数据处理能力,从而能够通过数据优势带来模型训练成果的差异。例如,阿里在研发M6时,构建了最大的中文多模态预训练数据集M6-Corpus,包含超过1.9TB图像和292GB文本,涵盖百科全书、网页爬虫、问答、论坛、产品说明等数据来源,并设计了完善的清洁程序以确保数据质量。百度ERNIE模型的训练数据集中也运用了大量百度百科、百度搜索以及百度知识图谱等生态内数据,通过更高质量的数据保障了模型的训练效果。 |
| 资源投入 | 互联网厂商重研发投入,资金及人才实力领先。大模型的训练需要较高且可持续的研发投入,头部互联网企业兼具高资本密度和高人才密度优势。资金方面,2022年,腾讯/阿里/百度研发费用达614/567/233亿元,明显领先于行业相关公司。人才方面,根据脉脉人才库,在计算机视觉、深度学习、语音识别、自然语言处理4个人工智能重要的技术方向上,互联网大厂是人才储备最丰富的企业。持续的高研发投入以及极高的人才密度有望驱动头部互联网企业保持在AI及大模型领域的领先优势。 |
资料来源:观研天下整理(zlj)

【版权提示】观研报告网倡导尊重与保护知识产权。未经许可,任何人不得复制、转载、或以其他方式使用本网站的内容。如发现本站文章存在版权问题,烦请提供版权疑问、身份证明、版权证明、联系方式等发邮件至kf@chinabaogao.com,我们将及时沟通与处理。






